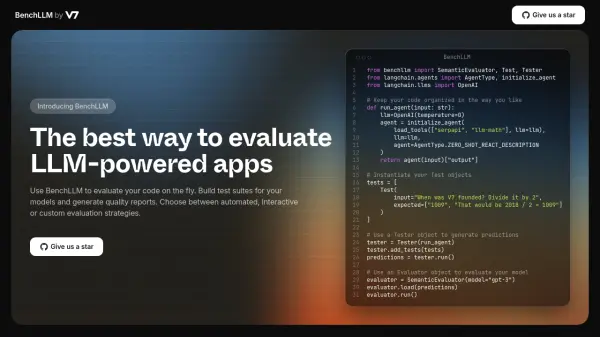
What is Conviction?
Conviction provides a comprehensive platform for developers working with Large Language Models (LLMs), aiming to address the challenges of unreliability and time-consuming testing. It enables teams to systematically evaluate LLM performance, identify issues like hallucinations, and compare different prompt templates or models side-by-side. This facilitates data-driven decisions in the development cycle, helping to improve the quality and consistency of LLM outputs.
Beyond initial testing, Conviction offers tools for monitoring LLM applications once deployed in production. Users can track performance over time, detect regressions quickly, and monitor associated costs. The platform also incorporates red teaming capabilities to proactively test for vulnerabilities such as prompt injections, jailbreaks, and potential data leakage, enhancing the overall safety and security posture of LLM-powered applications. Integration with popular frameworks and models like Langchain, LlamaIndex, OpenAI, and Anthropic is supported via SDKs.
Features
- LLM Evaluation & Testing: Systematically test prompt templates and compare model performance.
- Hallucination Detection: Identify and flag inaccurate or fabricated information generated by LLMs.
- Custom Evaluators: Define unique metrics tailored to specific application requirements.
- Production Monitoring: Track LLM app performance, costs, and user feedback in real-time.
- Regression Detection: Automatically identify drops in performance or quality after updates.
- Red Teaming Capabilities: Test LLM security against jailbreaks, prompt injections, and data leakage.
- Human Feedback Integration: Incorporate user or expert feedback into the evaluation loop.
- SDK Integration: Supports Python & JS SDKs for easy integration with existing workflows (Langchain, LlamaIndex, etc.).
Use Cases
- Evaluating the performance of different LLMs for a specific task.
- Testing and optimizing prompt templates to improve output quality.
- Detecting and mitigating hallucinations in LLM responses.
- Monitoring deployed LLM applications for performance regressions and cost control.
- Comparing results from various foundation models (e.g., OpenAI vs. Anthropic).
- Performing security testing (red teaming) on LLM applications.
- Establishing a systematic LLM testing and validation process.
- Incorporating human feedback for continuous model improvement.
Related Queries
Helpful for people in the following professions
Conviction Uptime Monitor
Average Uptime
0%
Average Response Time
0 ms