ReddRadar
ReddRadar
What is TheFastest.ai?
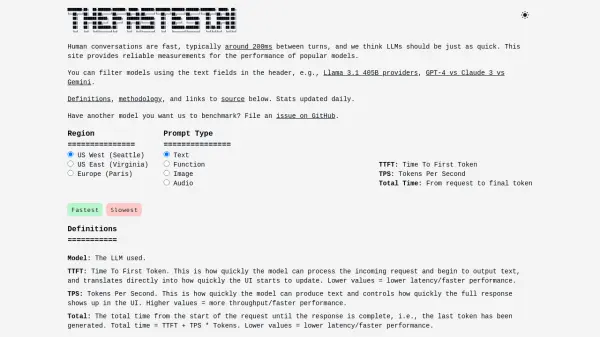
TheFastest.ai offers comprehensive and reliable performance measurements for widely used Large Language Models (LLMs). The platform benchmarks models based on key metrics like Time To First Token (TTFT), which indicates the initial response speed, and Tokens Per Second (TPS), reflecting the text generation rate. These measurements help users understand the real-world speed and responsiveness of different LLMs.
Benchmarks are conducted daily across multiple data centers (US West, US East, Europe) and consider various prompt types, including text, function calls, images, and audio. The methodology involves warming up connections, measuring TTFT from request start to the first token received, using standardized input/output token counts, and selecting the best result from three inferences to ensure accuracy and eliminate outliers. All raw data and benchmarking tools are publicly available.
Features
- LLM Performance Benchmarking: Measures TTFT and TPS for popular models.
- Multi-Region Testing: Runs benchmarks in US West (Seattle), US East (Virginia), and Europe (Paris).
- Multiple Prompt Types: Supports testing with text, function, image, and audio prompts.
- Daily Updates: Provides fresh performance statistics every day.
- Transparent Methodology: Details the benchmarking process, including connection warmup and outlier removal.
- Open Data & Tools: Offers public access to raw data (GCS bucket) and benchmarking tools (GitHub repo).
Use Cases
- Comparing the speed of different LLM providers (e.g., GPT-4 vs Claude 3 vs Gemini).
- Selecting the fastest LLM for latency-sensitive applications.
- Evaluating LLM performance across different geographical regions.
- Understanding the response time differences for various prompt types (text, function, image, audio).
- Monitoring LLM performance trends over time.
FAQs
-
What is TTFT?
TTFT stands for Time To First Token. It measures how quickly an LLM processes a request and starts generating output, indicating initial responsiveness. Lower values mean faster performance. -
What is TPS?
TPS stands for Tokens Per Second. It measures how quickly an LLM generates text after the initial response, indicating the throughput. Higher values mean faster performance. -
How often are the benchmarks updated?
The performance statistics are updated daily. -
Where is the benchmark data stored?
All raw benchmark data is publicly available in a GCS bucket linked on the site. -
What regions are used for testing?
Testing is currently conducted in US West (Seattle), US East (Virginia), and Europe (Paris).