What is Zeroscope?
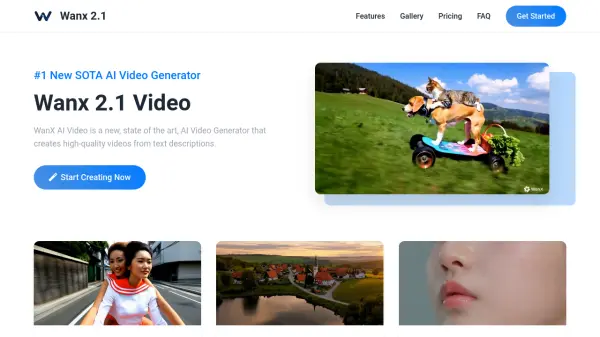
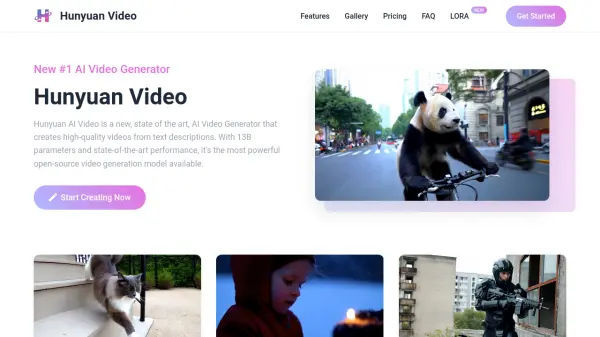
Zeroscope v2 is an open-source artificial intelligence model designed for text-to-video generation. Based on Damo's original text-to-video model and fine-tuned by @cerspense, it enables users to create short video clips simply by providing a text prompt. A key feature of Zeroscope is its ability to produce videos at a resolution of 1024x576 pixels without any embedded watermarks, offering clean output for various uses.
The recommended workflow involves a two-step process for optimal results. Users should first generate videos using the '576w' model at a lower resolution (576x320). Once a satisfactory video is created, it can be upscaled to the target 1024x576 resolution using the 'xl' model. This method helps maintain coherency compared to direct high-resolution generation. Users can adjust several parameters, including the number of frames (optimal at 24), frames per second (FPS) for smoothness, guidance scale (prompt adherence, optimal range 10-15), and the number of inference steps (balancing quality and generation speed, starting around 50).
Features
- Text-to-Video Generation: Creates short videos based on user-provided text prompts.
- Open-Source Model: Based on a fine-tuned version of Damo's text-to-video model.
- Watermark-Free Output: Generates videos without embedded watermarks.
- High-Resolution Upscaling: Supports upscaling videos to 1024x576 resolution using a dedicated 'xl' model.
- Parameter Control: Allows adjustment of frames, FPS, guidance scale, and inference steps for customized results.
Use Cases
- Creating short video clips from text descriptions.
- Generating visual content for social media or marketing.
- Experimenting with AI-driven video synthesis.
- Producing B-roll footage based on specific prompts.
- Visualizing concepts or stories described in text.
FAQs
-
What is the optimal number of frames for Zeroscope v2?
The model was trained on 24 frame clips, so setting num_frames to 24 yields the best results. Longer clips beyond 40 frames may degrade significantly. -
How does the guidance scale affect the video output?
It controls how closely the model follows the prompt. A scale between 10 and 15 is recommended. Too low results in a grayscale mess, too high causes distortion and color artifacts. -
What's the recommended process for generating high-resolution videos with Zeroscope?
Generate initially with the 576w model at 576x320 resolution, then upscale the desired result to 1024x576 using the xl model with the same prompt and an init_weight (e.g., 0.2). -
How can I make the generated videos smoother?
For optimal smoothness, generate at 24 fps. Alternatively, generate at 12 or 8 fps for a longer duration (2s or 3s from 24 frames) and then use an external video interpolation tool like RunwayML or Topaz Video AI to smooth the motion. -
What do the inference steps control?
Inference steps determine the number of iterations used to generate the video. More steps generally improve quality and coherency but take longer. Fewer steps are faster for experimentation but result in lower quality. Going above 100 steps usually doesn't improve the video.
Related Queries
Helpful for people in the following professions
Zeroscope Uptime Monitor
Average Uptime
3.45%
Average Response Time
4.9 ms