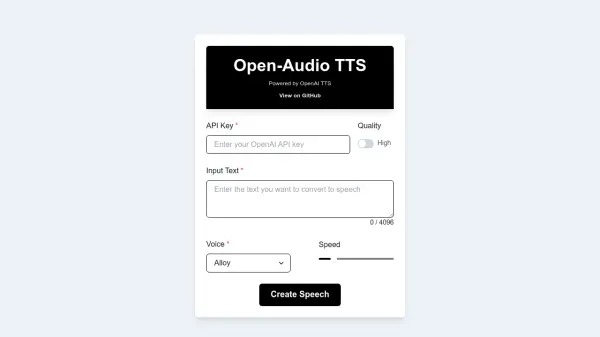
What is Open-Audio TTS?
Open-Audio TTS provides a straightforward interface for generating speech from text using the powerful OpenAI Text-to-Speech (TTS) engine. Users can input their text, up to a limit of 4096 characters, and leverage OpenAI's technology for conversion into audible speech.
The tool offers customization options, allowing users to select from different voice profiles including Alloy, Echo, Fable, Onyx, Nova, and Shimmer. Additionally, users can adjust the speech speed and select the desired audio quality. Operation requires an OpenAI API key, indicating reliance on OpenAI's backend infrastructure. A link to its GitHub repository is provided for those interested in the underlying code or further development.
Features
- OpenAI TTS Integration: Leverages OpenAI's advanced text-to-speech engine for audio generation.
- Multiple Voice Options: Offers a selection of voices including Alloy, Echo, Fable, Onyx, Nova, and Shimmer.
- Speed Control: Allows users to adjust the playback speed of the generated speech.
- Quality Selection: Provides an option to choose high audio quality.
- Text Input Limit: Accepts input text up to 4096 characters.
Use Cases
- Generating voiceovers for videos or presentations.
- Creating audio versions of articles or blog posts.
- Developing accessibility features requiring text-to-speech functionality.
- Prototyping voice user interfaces or applications.
- Producing audio content for podcasts or e-learning materials.
Related Queries
Helpful for people in the following professions
Open-Audio TTS Uptime Monitor
Average Uptime
0%
Average Response Time
0 ms