ReddRadar
ReddRadar

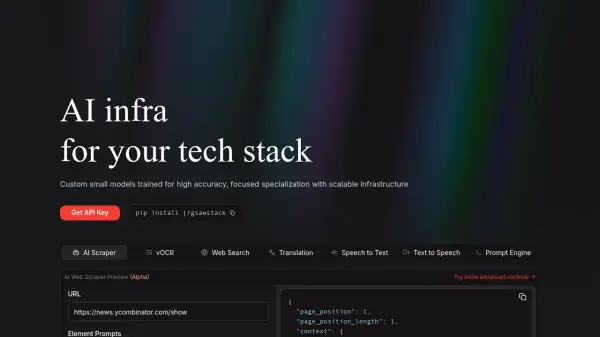
What is JigsawStack?
JigsawStack provides developers with access to a collection of specialized Artificial Intelligence models designed for specific tasks, emphasizing accuracy and performance. The platform offers scalable infrastructure, allowing applications to handle large volumes of requests efficiently. It focuses on delivering structured data outputs consistently across its various models, simplifying integration into existing technology stacks.
Integration is facilitated through fully typed Software Development Kits (SDKs) for multiple programming languages, comprehensive documentation, and ready-to-use code snippets. The platform includes features for observability, such as real-time logs and analytics, enabling users to monitor usage, debug issues, and track various data points. Security and privacy are prioritized, offering secure instances and fine-grained access control for API keys. Additionally, JigsawStack's models are designed with global use in mind, supporting over 160 languages and utilizing diverse training datasets.
Features
- AI Web Scraper: Scrape websites by providing prompts.
- vOCR: Extract text from images and various document types.
- Web Search: Integrate web search capabilities into AI applications.
- Translation: Translate text between numerous languages.
- Image Generation: Create images using models like SD1.5, SDXL, LoRAs, and DALL-E 3.
- Prediction: Perform zero-shot forecasting without requiring training data.
- Speech to Text: Transcribe audio and video content into text quickly.
- Text to Speech: Generate natural-sounding speech audio from text input.
- Prompt Engine: Automatically select and run prompts on the most suitable Large Language Model (LLM).
- Sentiment Analysis: Analyze and understand the emotions expressed in text.
- NSFW Detection: Identify nudity or sexual content within images.
- Embedding: Generate multimodal embeddings for various media types.
- Structured Data Output: Receive consistent, structured responses from all models.
- Automatic Scaling: Serverless infrastructure capable of handling billions of concurrent requests.
- Easy Integration: Offers fully typed SDKs, clear documentation, and code snippets.
- Observability: Provides real-time logs and analytics for monitoring and debugging.
- Multilingual Support: Global support for over 160 languages across models.
Use Cases
- Automating data extraction from websites using natural language prompts.
- Digitizing text content from scanned documents and images.
- Enhancing applications with real-time web search results.
- Building multilingual applications with automated translation.
- Generating custom images for marketing, design, or content.
- Predicting future trends or values without model training.
- Transcribing interviews, meetings, or audio/video content.
- Creating voiceovers or audio versions of textual content.
- Optimizing prompts for better results from large language models.
- Monitoring brand sentiment or customer feedback automatically.
- Moderating user-generated content by detecting NSFW images.
- Developing recommendation systems or semantic search using embeddings.
FAQs
-
How are tokens calculated?
Tokens are calculated based on the number of input and output characters in a request and the time taken (in milliseconds) to process the request. 1 ms of processing time equals 1 token. For example, a request with 100 input tokens, 200 output tokens, and 3000ms processing time uses 100 + 200 + 3000 = 3300 tokens. -
How is duration calculated for token usage?
Duration is based on the server-side processing time in milliseconds (ms). 1 ms equals 1 token, and 1 second equals 1000 tokens. Network latency is not included. -
How are file inputs or outputs calculated in token usage?
File uploads are free and not counted towards token usage. If a model outputs a file, the size of the output file is used to calculate the output tokens. -
What happens if I exceed my plan's token limits?
On the free plan, requests will be paused if the limit is reached. Paid plans do not have a fixed limit; usage beyond the included amount is billed at the end of the cycle. -
Will I be charged for API errors?
You will not be charged for server-related errors (status code 500). However, you will be charged for invalid requests made by the user (status code 400).