ReddRadar
ReddRadar

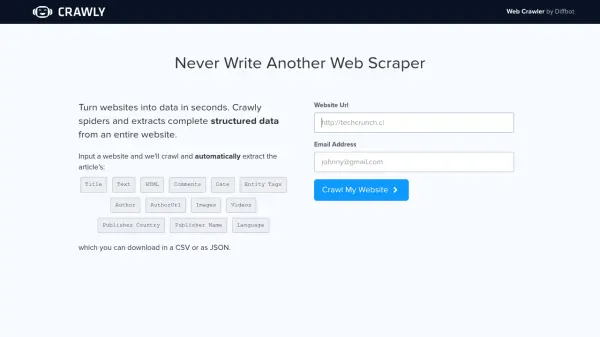
What is Crawly by Diffbot?
Crawly by Diffbot offers a powerful web crawling solution designed to transform websites into usable data quickly. Users can simply input a website URL, and the tool will automatically crawl the site, extracting structured information.
The extracted data includes elements such as article titles, text content, full HTML, comments, publication dates, entity tags, author details (name and URL), images, videos, publisher information (country and name), and language. This structured data can then be easily downloaded in either CSV or JSON format, saving users the effort of building and maintaining custom web scrapers.
The extracted data includes elements such as article titles, text content, full HTML, comments, publication dates, entity tags, author details (name and URL), images, videos, publisher information (country and name), and language. This structured data can then be easily downloaded in either CSV or JSON format, saving users the effort of building and maintaining custom web scrapers.
Features
- Automated Web Crawling: Spiders entire websites based on a provided URL.
- Structured Data Extraction: Automatically identifies and extracts key elements like title, text, HTML, comments, date, author, images, videos, publisher, and language.
- Multiple Download Formats: Offers extracted data in CSV and JSON formats.
- No Scraping Required: Eliminates the need for users to write custom web scrapers.
Use Cases
- Gathering data for market research
- Aggregating content from multiple sources
- Monitoring competitor websites
- Extracting product information for e-commerce analysis
- Building datasets for analysis or machine learning