ReddRadar
ReddRadar
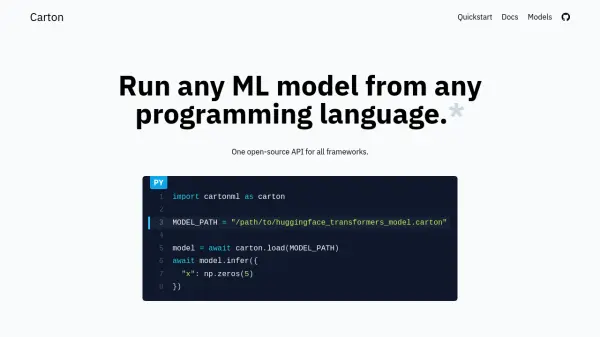
What is Carton?
Carton provides a unified, open-source solution for executing machine learning models across different programming languages and frameworks. It simplifies the deployment process by wrapping models, rather than converting them, which avoids potential errors and validation steps associated with format conversions like ONNX. This approach allows developers to maintain the use of original model features, including custom operations and optimizations like TensorRT.
The tool features a core implemented in optimized Rust, offering bindings for multiple languages such as Python, JavaScript, Rust, and more. Carton automatically handles the loading of models by identifying the required framework and version from metadata and fetching the appropriate "runner" component. This framework-agnostic API ensures that application code remains decoupled from specific ML framework implementations, facilitating easier updates and experimentation with new models. Carton is designed for low overhead, with preliminary benchmarks indicating minimal latency per inference call.
Features
- Model Packing: Wraps original models with metadata in a zip file without error-prone conversion.
- Automatic Runner Management: Reads metadata to select and fetch the appropriate framework runner for execution.
- Framework-Agnostic API: Allows running models from any supported framework using a single, consistent API.
- Multi-Language Bindings: Offers support for various programming languages including Python, JavaScript, Rust, C++, Java, Go, and more.
- Low Overhead Performance: Optimized Rust core ensures minimal latency during inference calls.
- Cross-Platform Support: Runs on x86_64/aarch64 Linux, macOS, with future plans for WebAssembly/WebGPU.
- Preserves Original Model Features: Supports custom ops and framework-specific optimizations like TensorRT.
Use Cases
- Deploying ML models without being tied to a specific framework.
- Simplifying the MLOps pipeline by standardizing model execution.
- Enabling teams using different programming languages to run the same ML models.
- Rapidly experimenting with and deploying cutting-edge models.
- Running models with custom operations or specific optimizations easily.
FAQs
-
Why not use ML frameworks like PyTorch or TensorFlow directly?
Carton decouples your inference code from specific frameworks, making it easier to adopt cutting-edge models without rewriting application logic. The framework becomes an implementation detail. -
How much overhead does Carton add?
Preliminary benchmarks show less than 100 microseconds (0.0001 seconds) overhead per inference call for small inputs, thanks to its optimized async Rust core. Further optimizations using Shared Memory are planned, especially for large inputs. -
What platforms does Carton support?
Currently supports x86_64 Linux/macOS, aarch64 Linux (e.g., AWS Graviton), and aarch64 macOS (Apple Silicon M1/M2). WebAssembly support is planned, initially for metadata access, with WebGPU runners coming soon. -
What is 'a carton' file?
A carton is the output of the packing step. It's a zip file containing the original model and metadata, without modifying the model itself, thus avoiding conversion errors. -
How does Carton compare to ONNX?
Carton wraps models, using the original framework (like PyTorch) for execution, which easily supports custom ops and avoids potentially problematic conversion steps. ONNX converts models. Carton plans to support running ONNX models as well.
Related Queries
Helpful for people in the following professions
Carton Uptime Monitor
Average Uptime
0%
Average Response Time
0 ms